

Datenbasierte Auswertungen sagen Verkehrsunfälle voraus
Verkehrsdaten sind ein wertvoller Schatz für die Untersuchung mobilitätsbezogener Fragestellungen. Die Wissenschaftler*innen des Zukunftslabors Mobilität werten diese Daten aus, um Verkehrsunfälle vorherzusagen und die Angebote von Shared Mobility und Micro Mobility zu verbessern.
Im Rahmen des Zukunftslabors Mobilität untersuchen die Wissenschaftler*innen innovative Dienstleistungen für den Transport von Personen und Gütern. Dazu analysieren und interpretieren sie Mobilitätsdaten und generieren somit datengetriebene Erkenntnisse. Besonders wertvoll sind Datenallianzen, bei denen sich Anbieter von Mobilitätsdienstleistungen zusammenschließen und ihre Daten miteinander teilen. Durch die Zusammenführung und Auswertung der Daten können z. B. Fahrerassistenzsysteme oder Verkehrsüberwachungssysteme verbessert werden. Wichtig ist, das Bedürfnis der Anbieter nach Privatsphäre und Sicherheit zu erfüllen. Dienstleister geben ihre Daten in der Regel nur ungern frei, aus Sorge vor Diebstahl, Missbrauch oder Wettbewerbsnachteilen.
Diesbezüglich arbeiten die Wissenschaftler*innen des Zukunftslabors Mobilität an Software-Architekturen und Methoden des föderierten Lernens, die eine sichere Datenauswertung ermöglichen. Dabei handelt es sich um eine Methode des Maschinellen Lernens (ML), bei der die Daten dezentral auf verschiedenen Datenplattformen analysiert und die Ergebnisse anschließend plattformübergreifend zusammengeführt werden. Dabei werden nicht die Rohdaten ausgetauscht, sodass die Dateneigentümer*innen keinen Missbrauch ihrer Daten fürchten müssen.
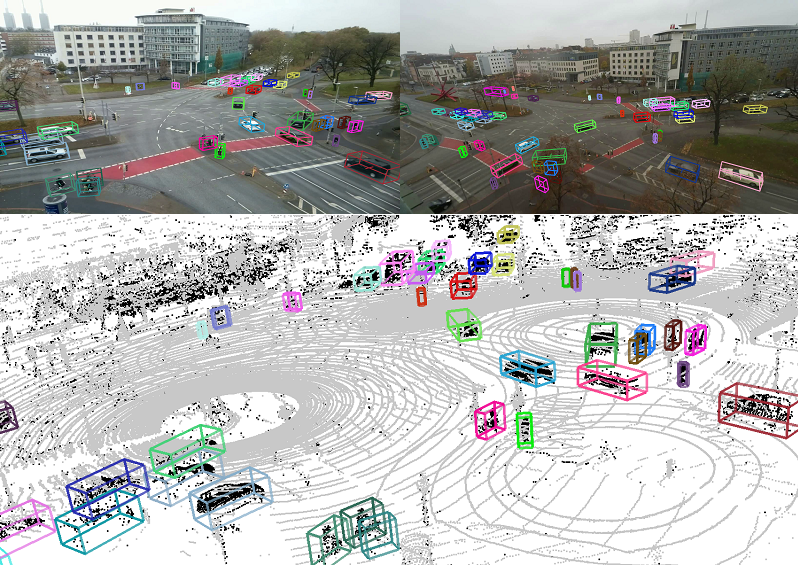
Föderiertes Lernen kann dazu eingesetzt werden, einen Unfall bzw. Beinahe-Unfall zu prognostizieren. Dies wird möglich, indem unnormales Fahrverhalten analysiert wird. In diesem Zusammenhang arbeiten wir an einem konkreten Anwendungsbeispiel – der „Intelligenten Kreuzung“. Hierbei werten wir Daten einer Kreuzung aus und ermitteln unnormales Fahrverhalten, das Unfälle verursachen kann. Um eine gute Datenbasis zu haben, erhoben wir an einer viel befahrenen Kreuzung in Hannover umfangreiche Bewegungsdaten verschiedener Fahrzeuge, Fußgänger*innen und Fahrradfahrer*innen.

Leibniz Universität Hannover, Institut für Kartographie und Geoinformatik
Dieser sog. LUMPI-Datensatz („Leibniz University Multi-Perspective Intersection Dataset“) beinhaltet Bildinformationen von drei Kameras und 3D-Punktwolken von fünf LiDAR-Sensoren sowie verifizierte Trajektorien (raumzeitliche Abfolge der Aufenthaltsdaten einer Person, eines Autos etc.) der Verkehrsteilnehmer*innen. Dadurch wird ersichtlich, wie Verkehrsteilnehmer*innen sich über die Kreuzung bewegen und wann. Wichtig ist dabei, dass die Identität und damit die Privatsphäre der Beteiligten geschützt wird, da in den verwendeten 3D-Punktwolken keine Identifikation von Einzelpersonen oder Fahrzeugen möglich ist. Die Wissenschaftler*innen kategorisierten die relevanten Daten und identifizierten Anomalien als Abweichungen von normalem Fahrverhalten bezogen auf Geschwindigkeit (z. B. plötzlicher Stopp, zu schnelles Fahren), Kreuzung (z. B. Missachtung der roten Ampel oder der Vorfahrt), Ort (z. B. U-Turn, falsche Fahrtrichtung) und weitere Informationen (z. B. nicht innerhalb der Fahrlinien fahren). Zur Bestimmung dieser Anomalien bauten die Wissenschaftler*innen eine Datenarchitektur auf, die durch den Einsatz von föderiertem Lernen Datenallianzen ermöglicht. Dazu entwickelten und untersuchten die Wissenschaftler*innen verschiedene Algorithmen, die sich für das föderierte Lernen und die Auswertung der Daten eignen.
Neben der Bearbeitung des Anwendungsfalls „Intelligente Kreuzung“ beschäftigen sich die Wissenschaftler*innen auch mit den Themen Shared Mobility und Micro Mobility, die im Personenverkehr eine zunehmend größere Bedeutung spielen. Bei der Shared Mobility bieten Dienstleister*innen Fahrzeuge an, die Nutzer*innen teilen können (z. B. Car Sharing). Die Micro Mobility ist für die individuelle Mobilität konzipiert und ermöglicht eine leichte und kompakte Fortbewegung mit Kleinstfahrzeugen (z. B. Fahrräder, E-Scooter und Segways). In beiden Fällen entstehen Mobilitätsdaten, z. B. über die Dauer der Nutzung, die Strecke oder den Wochentag. Aus diesen Daten können Erkenntnisse zur Nutzung von Shared Mobility und Micro Mobility gewonnen werden. Dies ist hilfreich, um die Interessen der Nutzer*innen besser zu verstehen und die Angebote der Dienstleister zu optimieren.
Die Wissenschaftler*innen wollen die Gründe und Ansprüche der Nutzer*innen sowie die bisherigen Praktiken der Anbieter datengetrieben ermitteln. Daher führten sie ein Webscraping von Shared-Mobility- und Micro-Mobility-Anbietern durch, um Nutzungsdaten zu erfassen. Beim Webscraping werden Daten und Inhalte von Websites mithilfe geeigneter Software ausgewertet. Diese Daten werden die Wissenschaftler*innen mit folgenden Daten anreichern, da sie potenzielle Einflussgrößen für die Nutzung der Dienste sind: Umweltdaten (Regularien, Mobilitätskosten für alternative Verkehrsträger, Soziokultur einer Region), externe Faktoren (öffentliche Verkehrspläne, lokale Ereignisse, Wetterdaten) und temporale Faktoren (Wochentag, Wochenende, Hauptreisezeiten, Ferien-/Urlaubszeiten). Daraus werden die Wissenschaftler*innen schließlich Handlungsempfehlungen für Mikromobilitätsanbieter zur Serviceoptimierung ableiten.
In diesem Zusammenhang führten die Wissenschaftler*innen eine Literaturanalyse durch, um Problemstellungen und ML-basierte Lösungsansätze in der Shared Mobility und Micro Mobility zu erfassen. Für eine intermodale Mobilität müssen unterschiedliche Fortbewegungsmittel (z. B. Autos, E-Scooter, Zug) aufeinander abgestimmt und Services zusammengefügt werden. Dafür ist es wichtig, Wegeketten zu bestimmen und zu optimieren. Im Rahmen der Literaturanalyse ermittelten die Wissenschaftler*innen, wofür Maschinelles Lernen bisher in der Micro Mobility eingesetzt wurde und welche Ansätze sie für die Wegekette nutzen können. Darauf aufbauend entwickeln die Wissenschaftler*innen ein Service-Framework, das grundlegende Informationen für Shared-Mobility-Anbieter zusammenstellt: Wann ist wo mit welchem Aufkommen zu rechnen? Wie gelangt eine Person von A nach B? Wann kann welcher Service genutzt werden?
2023 werden die Wissenschaftler*innen die durch das Webscraping ermittelten Daten analysieren, verschiedene statistische Verfahren und Verfahren des Maschinellen Lernens anwenden und die Einflüsse temporaler, räumlicher und wetterbedingter Faktoren auf das Verhalten der Micro-Mobility-Nutzer*innen näher untersuchen. Außerdem werden sie einzelne Schritte im Prozess des Serviceangebots von Micro Mobility Services mittels ML-Techniken optimieren.